
I recently encountered a requirement to estimate the size of (a lot of) nonclustered indexes on some very large tables due to not having a test box to create them on or the time to build one. I couldn’t find a script to do this, and as any programmer knows, laziness is the real mother of invention, so I wrote one.
This post summarises how we can calculate this and provides a Powershell function to do so.
I used Microsoft’s documentation as a basis on how to do it, but as it’s a wall of text that’s a little tricky to follow, I’ll go over the basics here. I’m only covering the leaf levels and non-MAX columns that would create LOB pages – I’ll explain why later.
Fundamentally we need to figure out the size of an index record, work out how many fit cleanly on a page, then calculate the total size.
So what’s in an index record?

This, as of SQL 2012, is the most basic record possible. It has;
- A header – 1 byte
- Null bitmap – minimum 3 bytes, an extra byte for every 8 total columns in the index (so 4 bytes for 9 columns, 5 bytes for 17, etc)
- Data row locator – this is either an 8-byte RID if the table is a heap, or the clustered index keys if not.
- The index columns themselves – however many columns (key or included) are in the index, aside from clustering keys which are in the DRL.
If there are any variable-length columns present in the index (key, row locator or included), there’s an extra section;

The ‘variable tracker’ is 2 bytes plus 2 bytes for every variable length column (including the uniquifier on a primary key, if it exists).
On top of this, each record takes an extra 2 bytes of a page’s slot array so it can be located – this isn’t on the diagrams as it isn’t part of the record itself.
So the script needs to do the following;
- Get the rowcount of the table
- Check if the table is a heap or has a clustered index
- If the table has a clustered index, is it unique? (does it have a uniquifier)
- Count the total number of columns (for the null bitmap)
- Count the number of variable-length columns
- Calculate the total size of a record, plus the 2 byte slot array entry
- Divide that size into 8096 bytes – the usable space on a page – rounding down as only entire rows are stored
- Divide that number into the rowcount of the table, and then we have the pages (and thus size) required.
As well as those, I added a few bits of functionality;
- Take a rowcount as a parameter, if we don’t want to hit a production table with COUNT_BIG()
- Take fillfactor as a parameter in case we’re not using 100 for some reason
- Keep track of null columns, as for versions prior to 2012, null bitmaps only exist on leaf pages if at least one column is null.
Script for the function Get-IndexSizeEstimate is at the bottom of the post and on github.
It takes an instance name, database, schema, string array of columns for the nonclustered index (including included columns) and optionally the rowcount and fill factor. The SQL and calculation blocks are documented so should be fairly self-explanatory combined with the above information – so onto some demos.
First, using a simple table I used for testing various cases, left as a heap, with 100k rows inserted to generate a few hundred pages;
CREATE TABLE dbo.IndexTesting
(
CustID INT NULL,
OrderID INT NOT NULL,
IndexCol1 INT NOT NULL,
IndexCol2 INT NULL,
VarIndexCol1 VARCHAR(4) NOT NULL,
VarIndexCol2 VARCHAR(10) NOT NULL
)
GO
INSERT INTO dbo.IndexTesting (CustID, OrderID, IndexCol1, IndexCol2, VarIndexCol1, VarIndexCol2)
VALUES (1,2,3,4,'test','test')
GO 100000If we want to create a single column index on IndexCol1 (4 bytes), the record should look like this;
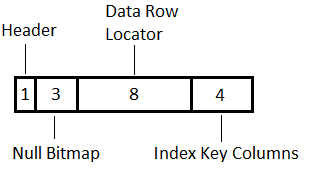
for a total of 16 bytes.
Run the script for a single column index on IndexCol1;
Get-IndexSizeEstimate -Instance SQL2017-VM01 -Database TestDB -Schema dbo -Table IndexTesting -Column 'IndexCol1'
We can see the use of the 8-byte RID as row locator, the minimum null bitmap and no variable-width bytes as expected.
Create the index and see if we’re close;
SELECT index_level, page_count, record_count, min_record_size_in_bytes, max_record_size_in_bytes, avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.IndexTesting'),2,NULL,'DETAILED')
SELECT SUM(used_page_count) * 8 / 1024 AS 'SizeMB'
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats p
ON p.[object_id] = i.[object_id]
AND i.index_id = p.index_id
WHERE i.[name] = 'ncx_test'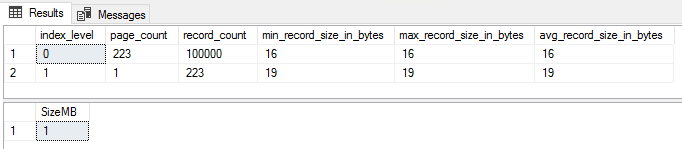
Bang on, 223 pages and 1MB.
Now for some more real-world examples.
A simple test case on a big table – using dbo.Posts from the StackOverflow2013 database, and choosing an index on OwnerUserId.
Get-IndexSizeEstimate -Instance SQL2017-VM01 -Database StackOverflow2013 -Schema dbo -Table Posts -Column 'OwnerUserId'
29658 pages and 232MB is the estimate – and note the row locator is now just 4 bytes, as it’s using the clustered index key instead of the RID in previous example.
Create the index and see how it stacks up (no pun intended);
CREATE NONCLUSTERED INDEX ncx_Posts_OwnerUserId
ON dbo.Posts (OwnerUserId)
SELECT index_level, page_count, record_count, min_record_size_in_bytes, max_record_size_in_bytes, avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Posts'),2,NULL,'DETAILED')
SELECT SUM(used_page_count) * 8 / 1024 AS 'SizeMB'
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats p
ON p.[object_id] = i.[object_id]
AND i.index_id = p.index_id
WHERE i.[name] = 'ncx_Posts_OwnerUserId'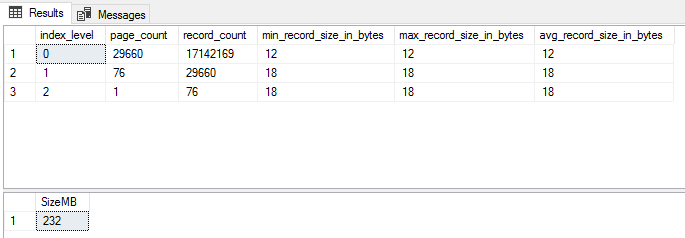
Not bad – just 2 pages out, and the same size after rounding to MB.
Now let’s go wide;
Get-IndexSizeEstimate -Instance SQL2017-VM01 -Database StackOverflow2013 -Schema dbo -Table Posts -Column 'Score','PostTypeId','CreationDate','FavoriteCount','OwnerUserId','ViewCount','LastActivityDate', 'ParentId'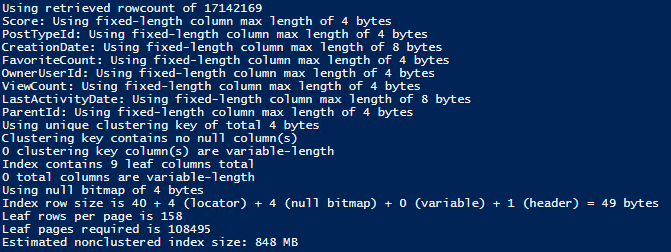
108495 pages and 848MB. Note how since we have 9 total columns in the index when including the primary key, the null bitmap has spilled into 4 bytes.
Build the index and take a look;
CREATE NONCLUSTERED INDEX ncx_Posts_WideIndex
ON dbo.Posts (Score,PostTypeId,CreationDate,FavoriteCount,OwnerUserId,ViewCount,LastActivityDate,ParentId)
SELECT index_level, page_count, record_count, min_record_size_in_bytes, max_record_size_in_bytes, avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Posts'),4,NULL,'DETAILED')
SELECT SUM(used_page_count) * 8 / 1024 AS 'SizeMB'
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats p
ON p.[object_id] = i.[object_id]
AND i.index_id = p.index_id
WHERE i.[name] = 'ncx_Posts_WideIndex'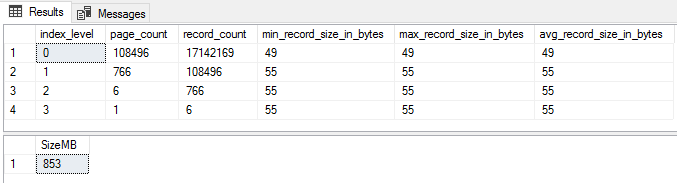
One page out and a 5MB undershoot – again, not bad!
This is also an example of how, even with a wide (in column number terms) index, the contribution of the non-leaf levels is minor.
They explain the 5MB discrepancy – and that’s just ~0.5% of the total size. This is the first reason I didn’t include calculations for the non-leaf levels of the index.
Now for an example of where the estimate can be way off.
Using dbo.Posts again, but this time estimating for an index on LastEditorDisplayName, which is a nullable NVARCHAR(40) column.
Get-IndexSizeEstimate -Instance SQL2017-VM01 -Database StackOverflow2013 -Schema dbo -Table Posts -Column 'LastEditorDisplayName'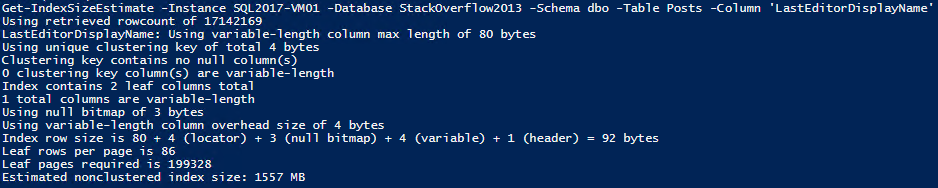
That’s ~200k pages and 1.5GB. Create the index and take a look;
CREATE NONCLUSTERED INDEX ncx_Posts_DisplayName
ON dbo.Posts (LastEditorDisplayName)
SELECT index_level, page_count, record_count, min_record_size_in_bytes, max_record_size_in_bytes, avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Posts'),3,NULL,'DETAILED')
SELECT SUM(used_page_count) * 8 / 1024 AS 'SizeMB'
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats p
ON p.[object_id] = i.[object_id]
AND i.index_id = p.index_id
WHERE i.[name] = 'ncx_Posts_DisplayName'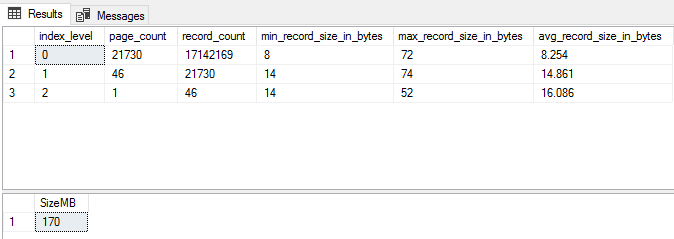
Ouch. That’s an order-of-magnitude overestimate. Why? Take a look at the record size figures. Min 8, max 72, and an average barely over the minimum.
Taking a glance at the table shows it appears to be sparsely populated, and with names that are much less than 40 characters to boot;
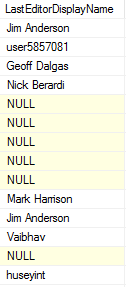
Well, there’s the rub. When variable length or null columns are included, the estimate can be nigh-on useless, depending on the distribution of data. Yep, there are things that could be done to get a better estimate – like taking a string array of parameters for ‘estimated null percent’ or ‘estimated varchar usage percent’, or going beyond guesses by calculating those figures from sampling/scanning the table…but at this point, a) the code starts getting increasingly complicated, b) we’re potentially needing to hit the database with some hefty queries and c) …it’s still not going to be completely accurate, so if it needs to be, we best get that test box set up. This is why I didn’t attempt to take non-leaf levels, LOB pages or variable-length column usage (script assumes maximum length) into account – it is an estimate, after all.
That said, I hope it proves useful to someone for the scenario it works well for – fixed-length column indexes. Code is below.
function Get-IndexSizeEstimate
{
<#
.SYNOPSIS
Returns estimated index size for a given column in a table
.DESCRIPTION
Calculates leaf-level index size for a given column in a table and returns the calculation and value in MB
.PARAMETER Instance
Specifies the SQL instance name
.PARAMETER Database
Specifies the database name
.PARAMETER Schema
Specifies the schema name
.PARAMETER Table
Specifies the table name
.PARAMETER Column
Specifies the column name(s)
.PARAMETER Rows
Specifies the number of rows to calculate for instead of querying the table for COUNT()
.PARAMETER Fillfactor
Specifies the fillfactor (1-100) to use (default 100)
.OUTPUTS
Index leaf-level estimated size
.EXAMPLE
PS> Get-IndexSizeEstimate -Instance SQL2017-VM01 -Database TestDB -Schema dbo -Table IndexTesting -Column IndexCol1,VarIndexCol2
Using retrieved rowcount of 100000
Using variable-length column max length of 4 bytes
Using unique clustering key of total 4 bytes
Clustering key contains no null column(s)
0 clustering key column(s) are variable-length
Index contains 2 leaf columns total
1 total columns are variable-length
Using null bitmap of 3 bytes
Using variable-length column overhead size of 4 bytes
Index row size is 4 + 4 + 3 (null bitmap) + 4 (variable) + 1 (header) = 16 bytes
Leaf rows per page is 449
Leaf pages required is 223
Estimated nonclustered index size: 2 MB
#>
param
(
[Parameter(position=0, mandatory=$true)][string]$Instance,
[Parameter(position=1, mandatory=$true)][string]$Database,
[Parameter(position=2, mandatory=$true)][string]$Schema,
[Parameter(position=3, mandatory=$true)][string]$Table,
[Parameter(position=4, mandatory=$true)][string[]]$Column,
[Parameter(position=5, mandatory=$false)][long]$Rows,
[Parameter(position=6, mandatory=$false)][int]$Fillfactor
)
Import-Module SqlServer
###### Pre-checks ######
# Parameter checks
if($Rows -and $Rows -lt 1)
{
Write-Output "Rows parameter must be at least 1"
return
}
if($Fillfactor -and ($Fillfactor -le 0 -or $Fillfactor -gt 100))
{
Write-Output "Fillfactor must be an integer between 1 and 100"
return;
}
# Check database exists and is online
$query = "SELECT 1
FROM sys.databases
WHERE [name] = '$($Database)'
AND state_desc = 'ONLINE'"
try
{
$check = Invoke-Sqlcmd -ServerInstance $Instance -Database master -Query $query -ConnectionTimeout 3 -QueryTimeout 3 -ErrorAction Stop
if(!$check)
{
Write-Output "Error - database does not exist or is offline."
return
}
}
catch
{
Write-Output "Error - can't connect to instance."
Write-Output $error[0]
return
}
# Check schema/table/column(s) exists
foreach($col in $Column)
{
$query = "SELECT 1
FROM sys.tables t
INNER JOIN sys.schemas s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.columns c
ON t.[object_id] = c.[object_id]
INNER JOIN sys.types ty
ON c.user_type_id = ty.user_type_id
WHERE s.[name] = '$($Schema)'
AND t.[name] = '$($Table)'
AND c.[name] = '$($col)'"
try
{
$check = Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 10 -QueryTimeout 300 -ErrorAction Stop
if(!$check)
{
Write-Output "Error - schema/table/column doesn't exist for $($col)"
return;
}
}
catch
{
Write-Output "Error connecting to instance."
Write-Output $error[0]
return
}
}
# Get SQL version
$query = "SELECT SUBSTRING(CONVERT(VARCHAR(128), SERVERPROPERTY('productversion')), 1, CHARINDEX('.', CONVERT(VARCHAR(128), SERVERPROPERTY('productversion')), 1) - 1) AS 'Version'"
try
{
[int]$sqlversion = (Invoke-Sqlcmd -ServerInstance $Instance -Database master -Query $query -ConnectionTimeout 5 -QueryTimeout 5 -ErrorAction Stop).Version
}
catch
{
Write-Output "Error retrieving SQL version"
Write-Output $error[0]
return
}
###### Code body ######
# Variable decarations
$leafcolumns = 0
$keylength = 0
$nullcolumns = $false
$nullbitmap = 0
$variablecolumns = 0
$variableoverheadsize = 0
$variablecolumnlist = 'text', 'ntext', 'image', 'varbinary', 'varchar', 'nvarchar'
# Get rowcount of table if not passed as parameter
if($Rows)
{
$rowcount = $Rows
Write-Output "Using passed rowcount of $($rowcount)"
}
else
{
$query = "SELECT COUNT_BIG(*) AS 'Rowcount'
FROM $($Schema).$($Table)"
try
{
$rowcount = (Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 10 -QueryTimeout 300 -ErrorAction Stop).Rowcount
if($rowcount -eq 0)
{
Write-Output "Table is empty. Aborting function"
return
}
Write-Output "Using retrieved rowcount of $($rowcount)"
}
catch
{
Write-Output "Error retrieving rowcount."
Write-Output $error[0]
return
}
}
# Get key column(s) length/nullability and increment leaf and variable key counters
foreach($col in $Column)
{
$query = "SELECT c.is_nullable, c.max_length AS 'MaxLength', ty2.[Name]
FROM sys.tables t
INNER JOIN sys.schemas s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.columns c
ON t.[object_id] = c.[object_id]
INNER JOIN sys.types ty
ON c.user_type_id = ty.user_type_id
INNER JOIN sys.types ty2
ON ty.system_type_id = ty2.user_type_id
WHERE s.[name] = '$($Schema)'
AND t.[name] = '$($Table)'
AND c.[name] = '$($col)'"
try
{
$result = Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 5 -QueryTimeout 5 -ErrorAction Stop
$keylength += $result.MaxLength
$leafcolumns++
# Set null columns flag true if index column is nullable (used for SQL < 2012)
if($result.is_nullable)
{
$nullcolumns = $true
}
if($variablecolumnlist -contains $result.Name)
{
$variablecolumns++
Write-Output "$($col): Using variable-length column max length of $($result.MaxLength) bytes"
}
else
{
Write-Output "$($col): Using fixed-length column max length of $($result.MaxLength) bytes"
}
}
catch
{
Write-Output "Error retrieving column max length"
Write-Output $error[0]
return
}
}
# Get clustered index size, nullability, column count and uniqueness (if exists)
$query = "SELECT i.is_unique, MAX(CAST(is_nullable AS TINYINT)) AS 'NullColumns', COUNT(*) AS 'NumKeyCols', SUM(c.max_length) AS 'SummedMaxLength'
FROM sys.tables t
INNER JOIN sys.schemas s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.indexes i
ON t.[object_id] = i.[object_id]
INNER JOIN sys.index_columns ic
ON i.[object_id] = ic.[object_id]
AND i.index_id = ic.index_id
INNER JOIN sys.columns c
ON ic.[object_id] = c.[object_id]
AND ic.column_id = c.column_id
WHERE s.[name] = '$($Schema)'
AND t.[name] = '$($Table)'
AND i.[type] = 1
GROUP BY i.is_unique"
try
{
$clusteringkey = Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 5 -QueryTimeout 5 -ErrorAction Stop
# If there's no clustering key
if(!$clusteringkey)
{
# Use value for heap RID (8 bytes)
$rowlocatorlength = 8
Write-Output "Table is a heap, using RID of 8 bytes"
}
else
{
# Increment leaf column count by clustering key count
$leafcolumns += $clusteringkey.NumKeyCols
if($clusteringkey.is_unique -eq 1)
{
$rowlocatorlength = $clusteringkey.SummedMaxLength
Write-Output "Using unique clustering key of total $($rowlocatorlength) bytes"
}
else
{
# Need to add 4 bytes for uniquifier, and also increment $variablecolumns
$rowlocatorlength = $clusteringkey.SummedMaxLength + 4
$variablecolumns++
Write-Output "Using nonunique clustering key of total $($rowlocatorlength) bytes with uniquifier"
}
# Check if any null columns exist in clustering key and set flag if so
if($clusteringkey.NullColumns -eq 1)
{
$nullcolumns = $true
Write-Output "Clustering key contains null column(s)"
}
else
{
Write-Output "Clustering key contains no null column(s)"
}
# Get count of clustering key variable colunns
$query = "SELECT COUNT(*) AS 'Count'
FROM sys.tables t
INNER JOIN sys.schemas s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.indexes i
ON t.[object_id] = i.[object_id]
INNER JOIN sys.index_columns ic
ON i.[object_id] = ic.[object_id]
AND i.index_id = ic.index_id
INNER JOIN sys.columns c
ON ic.[object_id] = c.[object_id]
AND ic.column_id = c.column_id
INNER JOIN sys.types ty
ON c.user_type_id = ty.user_type_id
INNER JOIN sys.types ty2
ON ty.system_type_id = ty2.user_type_id
WHERE s.[name] = '$($schema)'
AND t.[name] = '$($Table)'
AND i.[type] = 1
AND ty2.[name] IN ('text', 'ntext', 'image', 'varbinary', 'varchar', 'nvarchar')"
$variableclusteringcolumns = (Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 5 -QueryTimeout 5 -ErrorAction Stop).Count
Write-Output "$($variableclusteringcolumns) clustering key column(s) are variable-length"
$variablecolumns += $variableclusteringcolumns
}
}
catch
{
Write-Output "Error retrieving clustering key info"
Write-Output $error[0]
return
}
Write-Output "Index contains $($leafcolumns) leaf columns total"
if(($nullcolumns) -and ($sqlversion -lt 11))
{
Write-Output "Leaf record contains null columns"
}
Write-Output "$($variablecolumns) total columns are variable-length"
# Calculate null bitmap size
# If version is >= 2012 or null columns exist, add null bitmap - else don't add
if(($sqlversion -ge 11) -or ($nullcolumns -eq $true))
{
$nullbitmap = [Math]::Floor(2 + (($leafcolumns + 7) / 8))
Write-Output "Using null bitmap of $($nullbitmap) bytes"
}
# Calculate variable-length overhead size
if($variablecolumns -gt 0)
{
$variableoverheadsize = 2 + ($variablecolumns * 2)
Write-Output "Using variable-length column overhead size of $($variableoverheadsize) bytes"
}
# Calculate total index size
$indexsize = $keylength + $rowlocatorlength + $nullbitmap + $variableoverheadsize + 1
Write-Output "Index row size is $($keylength) + $($rowlocatorlength) (locator) + $($nullbitmap) (null bitmap) + $($variableoverheadsize) (variable) + 1 (header) = $($indexsize) bytes"
# Calculate leaf rows per page - adding 2 bytes to indexsize for slot array entry
$leafrowsperpage = [Math]::Floor(8096 / ($indexsize + 2))
Write-Output "Leaf rows per page is $leafrowsperpage"
# Use full pages if not specifying fillfactor
if(!$Fillfactor)
{
$leafpages = [Math]::Ceiling($rowcount / $leafrowsperpage)
Write-Output "Leaf pages required is $($leafpages)"
}
else
{
Write-Output "Using fillfactor of $($Fillfactor)"
$freerowsperpage = [Math]::Floor(8096 * ((100 - $Fillfactor) / 100) / ($indexsize + 2))
$leafpages = [Math]::Ceiling($rowcount / ($leafrowsperpage - $freerowsperpage))
Write-Output "Leaf pages required is $($leafpages)"
}
###### Final result ######
$estimate = $leafpages * 8192
$estimateMB = [Math]::Round($estimate / 1024 / 1024)
Write-Output "Estimated nonclustered index size: $($estimateMB) MB"
}
Nice post, but for the row count, just grab sum(rows) from sys.partitions where index_id in (0,1) instead of count_big against the table … we’re just talking about estimates here, right? 🙂
Thanks Aaron – and good call on sys.partitions, I’d forgot about that DMV. I’ll add a parameter for that – cheers!
Aaron, sum(rows) does not return the right count, I gave it a go but it gave 106 548 404 whereas the script and select count(*) outputs 17 142 169
Nice and useful script, well done and thanks for making this available for the community