Hopefully not many people are still configuring SSIS instances on SQL 2012 or 2014 – especially HA instances – but if you are, this post is for you.
If you’re running SQL Server 2016 or above, having the SSIS catalog function correctly in an AG is supported by built-in functionality to manage the DMK (database master key). In 2012/2014 however there is no such support. Without intervention this makes SSISDB unable to be opened after a failover, because the DMK isn’t open – leading to errors such as “Please create a master key in the database or open the master key in the session before performing this operation.”
The fix for this is simply to open the DMK and re-encrypt it with the SMK (service master key) of the new primary replica;
USE SSISDB;
OPEN MASTER KEY DECRYPTION BY PASSWORD = 'password'
ALTER MASTER KEY ADD ENCRYPTION BY SERVICE MASTER KEYBut if you’ve put SSISDB into an AG then you almost certainly want this to happen automatically. So here is a framework for automating the process.
Assumptions;
– we have a single AG containing SSISDB
– a DBA admin database *not* included in the AG (or master) available – into which the tables and stored proc are deployed
– all artefacts are deployed to each instance.
– we have the password to the DMK!
First we create a table to contain the current replica role to act as a flag, and seed it with a single row;
CREATE TABLE [dbo].[ReplicaRole]
(
[CurrentRole] INT NOT NULL
)
INSERT INTO [dbo].[ReplicaRole] (CurrentRole)
SELECT [role]
FROM sys.dm_hadr_availability_replica_states
WHERE is_local = 1At this point the value in the table should be 1 on the primary replica and 2 on the secondary(ies).
Then we create a logging table to observe the history of the process and any failovers;
CREATE TABLE [dbo].[AutoFailoverLog]
(
[DateEntry] DATETIME NOT NULL DEFAULT GETDATE(),
[LastRole] INT NOT NULL,
[CurrentRole] INT NOT NULL,
[ReEncrypted] INT NOT NULL
)Now, a stored procedure to perform the following;
– Check what role the replica was the last time the SP was executed
– Get the current role
– If the replica was secondary but is now primary, open and re-encrypt the SSISDB key. Otherwise, take no action with regards to the key.
– Update the ‘current role’ flag and write the overall result to the logging table
CREATE PROCEDURE [dbo].[SSISDBAutoFailover]
AS
BEGIN
DECLARE @last_role TINYINT;
DECLARE @current_role TINYINT;
DECLARE @sql VARCHAR(1024);
SET @last_role = (SELECT CurrentRole
FROM [dbo].[ReplicaRole]);
SET @current_role = (SELECT [role]
FROM sys.dm_hadr_availability_replica_states
WHERE is_local = 1);
/* This means the last time the job ran, this node's role was secondary and now it's primary.
So we need to re-encrypt the SSISDB master key. */
IF (@last_role = 2 AND @current_role = 1)
BEGIN
SET @sql = 'USE SSISDB;
OPEN MASTER KEY DECRYPTION BY PASSWORD = ''password''
ALTER MASTER KEY ADD ENCRYPTION BY SERVICE MASTER KEY';
EXEC(@sql);
INSERT INTO dbo.AutoFailoverLog (LastRole, CurrentRole, ReEncrypted)
VALUES (@last_role, @current_role, 1)
END
ELSE
BEGIN
INSERT INTO dbo.AutoFailoverLog (LastRole, CurrentRole, ReEncrypted)
VALUES (@last_role, @current_role, 0)
END
-- Update current role flag
SET @sql = 'UPDATE dbo.ReplicaRole
SET CurrentRole = ' + CONVERT(VARCHAR(1),@current_role)
EXEC(@sql);
ENDFinally, create an Agent job to run the procedure frequently. How frequently depends on how often your SSIS packages execute and how stable your cluster is. I’ve had reliable results with a 5 minute frequency on a cluster on a robust network.
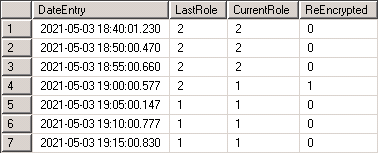
When a failover occurs, we should see something like the below snip in the AutoFailoverLog table – in this case, a failover occured between 18:55 and 19:00, triggering the LastRole = 2 and CurrentRole = 1 path and thus the re-encryption logged in the last column;
This isn’t a perfect solution;
– The DMK password is in the definition. This may or may not be a problem for you, depending on your security policies – if it is, you could look into encrypting the proc (not foolproof) or retrieving the password in the proc in a more secure method.
– Multiple failovers in a short period of time could break it. Say, a failover from server A to server B then back to A occurs in the period between executions – the DMK would not have been opened and re-encrypted on server A but the proc would not have picked up the failover.
To make it more robust, increasing the frequency of execution would help prevent missing multiple failovers. It’s lightweight, so no harm there. Beyond that – we would ideally have this code execute as a trigger based on a failover instead of a repeating state check. Unfortunately there’s no nice, built-in way to do this – but I would suggest hooking into one of the alerts that fires upon failover – check the eventlog and query sys.messages for AlwaysOn related error codes to dig out the right one to act on. I would look into this myself but a) this solution was sufficient for the particular solution in my care and b) at this point I’m hoping my involvement in pre-2016 SSIS AGs is done!