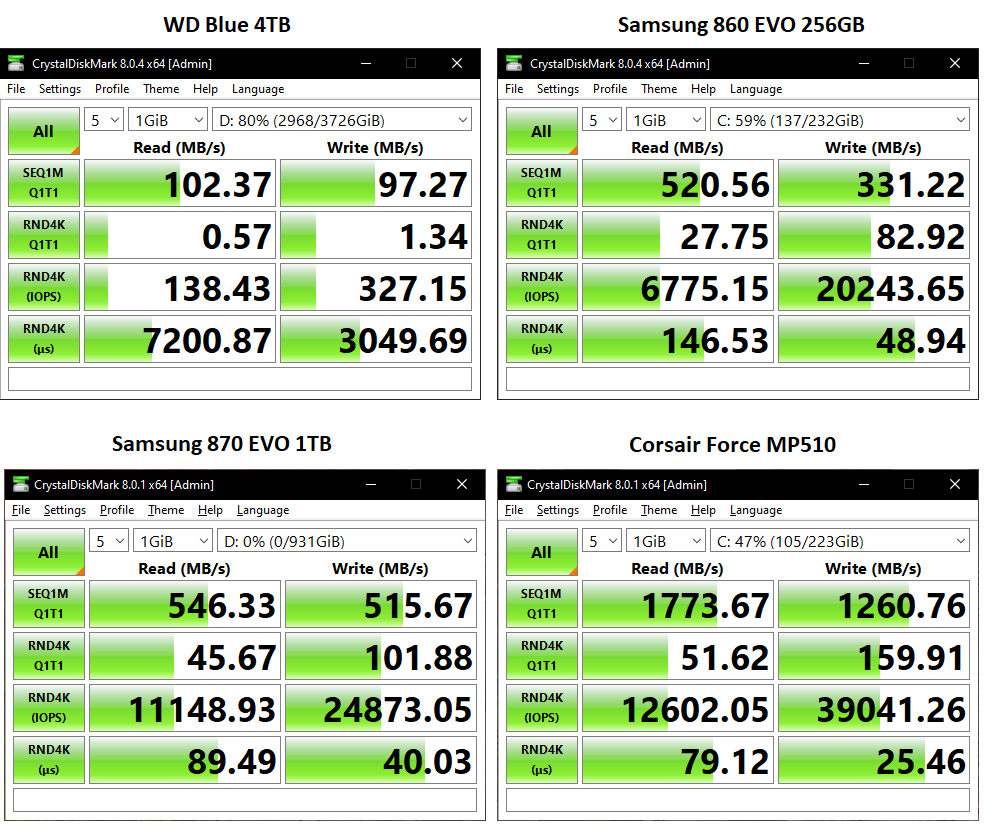
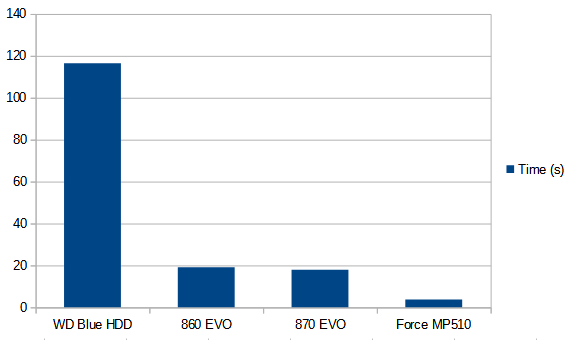
This month’s T-SQL Tuesday is about how we look at SQL Server upgrades, hosted by Steve Jones.

My experience of SQL upgrades is that they tend to be largely dictated by neccessity, either of the ‘the Security team is getting really twitchy about these old servers’ or ‘crap, it’s license renewal time and the vendor doesn’t support x’ variety. I’ve never performed one that wasn’t under some sort of pressure. How do we get here?
At this point I must mention the age old mantra…
if it ain’t broke, don’t fix it
They’re certainly wisdom in it, to a large extent. Accidentally applied patches and changes have wreaked plenty of havoc on systems across time and space.
The problem occurs when it’s stretched to breaking point.
That Windows 2000 box running SQL 2005 may not be ‘broke’ per se, but;
– people are scared of touching it. We shouldn’t be scared of servers – we should be careful, but confident we can handle them
– no vendor support for either OS or software should something actually break
– it’s probably a security risk
– expert knowledge to support the OS/software is harder to find
– the solution it provides is probably hampered in performance and modern resiliency features
– a dozen people probably already said ‘we’ll upgrade it at some point’ but never did
If this mantra is held onto too tightly, before we know it we end up with lots of difficult/costly to support old solutions and the concept of dealing with the situation spirals towards ‘unfeasible’.
I feel like generally management tend to veer too much to the conservative side and this is why we as DBAs or sysadmins face so much tech debt. The overall upgrade process always has risks, but if we’re talking about SQL Server itself, there are just not that many breaking changes. None, for example, for the SQL2019 database engine.
That said, I’m certainly not a proponent of being in a rush to upgrade to the latest major version. There are still too many potentially serious bugs that end up being ironed out in the first tranche of CUs, and I’d rather someone else discover these if possible. Right now, at the beginning of 2022, unless there’s a specific use case for an added feature in SQL2019, I’m also not in a rush to upgrade something still on 2016/2017 – they’re both mature, stable releases with robust HADR, Query Store support and a 4+ years of extended support left.
So, when to upgrade?
Here are three majors reasons to upgrade;
- When a solution is going to be around a while and SQL will go OOS during its lifespan. When calculating this, take the quoted remaining lifespan from management and triple it. Additionally, consider the wider estate. The higher the volume of tech debt building up, the quicker we need to get on top of it.
- When a solution has problems that can really benefit from an upgrade. There are loads of potential benefits here and YMMV in how much benefit is required for a business case, but, say, you have an old, flaky replication set up that could benefit from Availability Groups. Or a cripplying slow DW creaking under its own mass that could do with columnstore. Or you have plenty of spare VM cores and RAM, but run Standard Edition and have a resource-maxed system that would happily improve with the increased allowed resources from later versions.
- When you’re upgrading the underlying hardware/OS. There are two ways to look at this – either that we’re already introducing risk with such an upgrade so don’t take extra risk, or that since we’re going through the upheaval of an upgrade we may as well take advantage of it and upgrade SQL as well. I’ll generally take the latter, opportunist view.
How?
Before any other consideration, we need to scope out the work. Is it a small project – a single database/instance backend for a non-critical with generous downtime? Or is it a much bigger one – a vast reporting instance with connections coming in from all over the place, or a highly-available mission-critical system with hardly any downtime? This will define the resource needed – the bigger the impact/reach, the bigger the project, resource allocation and stakeholder involvement needs to be.
Upgrades can be in-place or to a new server – the new server option is infinitely preferable as it makes testing, rollout and rollback far easier and safer.
A few best practise tips;
- Have a technical migration checklist that covers everything SQL Server related – config, logins, credentials, jobs, proxies, etc etc. Go over the instance with a fine-toothed comb as there are plenty of odds and ends hidden away.
- Use a test environment and get a solid test plan worked out with both IT and users that covers as many bases as possible. As testing coverage approaches 100%, risk approaches 0%. Note the word ‘approaches’ – it’s never 0%. If we have business analysts/testers who can focus solely on parts of this task, great – they will extract things we would miss.
- Utilise the Database Migration Advisor to help catch any potential issues
- Have a solid rollback plan – and test it.
- Take the opportunity to document the solution as we go, if it hasn’t already been done.
- Also take the opportunity to do some cleanup, if scope allows. Unused databases, phantom logins, etc. The less we need to migrate, the better.
- Decide ahead of time which new features to enable, if any, and why. The same goes for fixing any outdated settings, like bumping CTFP up from 5. You may want/need to just leave everything as-is initially, but you might then have scope for a ‘phase 2’ where improvements are introduced once stability is established.
- Related to the above point, make use of the ability to keep Compatibility Mode at its existing level, if risk tolerance requires it.
- Post-migration, be sure to run CHECKDB (additionally using the DATA_PURITY option if a source database(s) was created prior to 2005) and update stats and views.
The Cloud
PaaS (Azure SQL DB, MI) changes things.
We don’t need to worry about upgrading anymore, because there’s one version of the product – constantly tested and updated by Microsoft. That’s great! – but it also means we’re at their mercy and they could potentially apply a patch that breaks something.
This is simply part of the great cloud tradeoff. We hand over responsibility for hardware, OS and software patching but at the same time lose control of it. We can’t have our cake and eat it, too.
But one thing to be said for surrendering this ability is that the more we use Azure – the more data Microsoft has to analyse, the more databases to test on, and the more reliable the whole process should get.
I think it’s a tradeoff worth making for systems suitable for Azure.