My first technical job was somewhat unusual. It was for a niche software company that made despatch software for taxi companies. It was a small company, but had the majority of the UK market as customers at the time, and offered 24/7 support, so was very busy. The company supplied their software, but also most of the applicable hardware – computers, networking, radio systems and mobile devices. I’d been a barman for the previous two years – I quit that job with the intention of going back to college to study some certifications to work in IT, but that fell through a day before they were due to start as nobody else wanted to do the courses, so they were cancelled. Out of necessity from suddenly having neither a job nor any educational funding, I hastily applied for a few tech support jobs, one of which offered an interview.
The interview was very informal. I was asked if I could take apart and put together a PC, which I could, though wasn’t made to prove it. And then some general Windows and hardware questions. The company was hesitant to hire me as I didn’t have a full degree – just a diploma in maths and computing – but I will have no doubt pleaded my case by telling them I’d started programming in BASIC while still in primary school, Visual Basic and C in my teens and spent a lot of hobby time since then messing about to various degrees with computers and coding – so I knew my way around Windows and software. I got the job, albeit on lower pay than usual given the lack of degree – and was given some thick printed-out booklets covering the ins and outs of their software, and every evening for the next few weeks, reading through those archaic texts was my life.
Fundamentally it was a tech support role. But what I had to support was where it got interesting – and challenging. First was the basic Windows kind of stuff – most customers had a mix of Windows Server 2003/2008 and WinXP, and we had the ability to remote into their sites to take control of the servers, so nothing too problematic there – but a handful of customers remained on DOS. Yep, DOS in…2011. This was the support call we dreaded. It meant no remoting, and having to talk (usually not very tech-savvy) people through troubleshooting via the CMD prompt and/or unplugging and plugging various serial cables to peform a physical DR switchover . Occasionally at 2am. That stuff was…character building.
Then there was the software on top. There was both a text-based, terminal style version, and a new GUI version. It was complicated software providing both despatching and accounting features, with extensive logging and hundreds of config flags hidden in the admin options that needed to be checked in the course of diagnosing problems. Fortunately, as well as the aforementioned manuals, there was an internal Wiki maintained by the developers documenting most of these config flags and processes, but this didn’t cover every new setting or, obviously, undiscovered bugs. We, the support team, added to this invaluable resource as we found new issues or new information about settings and processes.
Finally there was the hardware. Every taxi needed a device to communicate back to the office. At the time we were rolling out mobiles, but most customers still had radios. And thus I was introduced to the intersection of computers and radios – Moxa devices with Ethernet/Serial connections to link the server to the radio system. And radio comms logs in the software logging broadcast and received signals, retries, errors etc. Some issues we could diagnose ourselves, like areas of bad signal by piecing together radio logs with the map corresponding to different physical locations, but we also had a team of radio engineers we’d often have to take more complicated issues to.
It was a baptism of fire for a first technical job in many ways. Not only did we have to support typical Windows and networking issues, but also multiple versions of completely bespoke software, radio comms and accounting issues. For around a thousand customers, who each had their own unique configs, radio environments and incident history – and all depended on their software for their livelihoods. The team was small, and sometimes the phones would be ringing off the hook all day, especially around holidays when these companies were at their busiest. I had an extra challenge in that I had/have a mild stutter that, while not normally a problem, is worse on phones – so that was a case of adapt or die, quickly. Some of the customers, being external not internal, could be…well, rough around the edges would be an understatement. A few times I had threats someone was going to drive down and throw their system throw the office window. (they never did)
The on-call rotation, when I learned enough to join it, could be brutal. Sometimes we’d get a dozen calls in a night, and would turn up bleary-eyed at 8:45 the next day. The subsequent evening was almost always a total write-off – get home, sleep. I appreciated the extra money at the time, but it was the kind of sleep and health sacrifice only someone in their early 20s would reasonably choose to take!
Challenges aside, I’m forever thankful for that job (and for my bosses-to-be for taking the chance with me). We had good teams of people – the support team helping each other out massively – knowledgable old hands, had fun despite the challenges, and I got involved in things beyond application support – I’d completed my CCNA so I ended up doing a new standard router config, got involved in bug testing, and also picked up MySQL rollouts and support as I’d also been studying SQL. I learned a lot about how to communicate with non-technical people, manage expectations and deal with a very busy helpdesk by staying on top of the most important issues. Additionally, I got exposure to the fundamentals of software testing, the challenges developers face, and training new staff on the systems we supported.
I didn’t want to stay in a niche support role forever – and at the time, I saw the shadow of Uber looming on the horizon as an industry threat – so had explored both networking and SQL as progression routes, and ended up choosing SQL. After a few years I left the company, moving out of the trenches to a much quieter backend role supporting MSSQL-backed apps and subsequently into SQL/SSRS development and administration. It was the right move for me and I don’t miss the support life, but I will always have massive respect for tech support after being on the other side of the phone.
My experience of SQL upgrades is that they tend to be largely dictated by neccessity, either of the ‘the Security team is getting really twitchy about these old servers’ or ‘crap, it’s license renewal time and the vendor doesn’t support x’ variety. I’ve never performed one that wasn’t under some sort of pressure. How do we get here?
At this point I must mention the age old mantra…
if it ain’t broke, don’t fix it
They’re certainly wisdom in it, to a large extent. Accidentally applied patches and changes have wreaked plenty of havoc on systems across time and space.
The problem occurs when it’s stretched to breaking point. That Windows 2000 box running SQL 2005 may not be ‘broke’ per se, but; – people are scared of touching it. We shouldn’t be scared of servers – we should becareful, but confident we can handle them – no vendor support for either OS or software should something actually break – it’s probably a security risk – expert knowledge to support the OS/software is harder to find – the solution it provides is probably hampered in performance and modern resiliency features – a dozen people probably already said ‘we’ll upgrade it at some point’ but never did
If this mantra is held onto too tightly, before we know it we end up with lots of difficult/costly to support old solutions and the concept of dealing with the situation spirals towards ‘unfeasible’.
I feel like generally management tend to veer too much to the conservative side and this is why we as DBAs or sysadmins face so much tech debt. The overall upgrade process always has risks, but if we’re talking about SQL Server itself, there are just not that many breaking changes. None, for example, for the SQL2019 database engine.
That said, I’m certainly not a proponent of being in a rush to upgrade to the latest major version. There are still too many potentially serious bugs that end up being ironed out in the first tranche of CUs, and I’d rather someone else discover these if possible. Right now, at the beginning of 2022, unless there’s a specific use case for an added feature in SQL2019, I’m also not in a rush to upgrade something still on 2016/2017 – they’re both mature, stable releases with robust HADR, Query Store support and a 4+ years of extended support left.
So, when to upgrade?
Here are three majors reasons to upgrade;
When a solution is going to be around a while and SQL will go OOS during its lifespan. When calculating this, take the quoted remaining lifespan from management and triple it. Additionally, consider the wider estate. The higher the volume of tech debt building up, the quicker we need to get on top of it.
When a solution has problems that can really benefit from an upgrade. There are loads of potential benefits here and YMMV in how much benefit is required for a business case, but, say, you have an old, flaky replication set up that could benefit from Availability Groups. Or a cripplying slow DW creaking under its own mass that could do with columnstore. Or you have plenty of spare VM cores and RAM, but run Standard Edition and have a resource-maxed system that would happily improve with the increased allowed resources from later versions.
When you’re upgrading the underlying hardware/OS. There are two ways to look at this – either that we’re already introducing risk with such an upgrade so don’t take extra risk, or that since we’re going through the upheaval of an upgrade we may as well take advantage of it and upgrade SQL as well. I’ll generally take the latter, opportunist view.
How?
Before any other consideration, we need to scope out the work. Is it a small project – a single database/instance backend for a non-critical with generous downtime? Or is it a much bigger one – a vast reporting instance with connections coming in from all over the place, or a highly-available mission-critical system with hardly any downtime? This will define the resource needed – the bigger the impact/reach, the bigger the project, resource allocation and stakeholder involvement needs to be.
Upgrades can be in-place or to a new server – the new server option is infinitely preferable as it makes testing, rollout and rollback far easier and safer.
A few best practise tips;
Have a technical migration checklist that covers everything SQL Server related – config, logins, credentials, jobs, proxies, etc etc. Go over the instance with a fine-toothed comb as there are plenty of odds and ends hidden away.
Use a test environment and get a solid test plan worked out with both IT and users that covers as many bases as possible. As testing coverage approaches 100%, risk approaches 0%. Note the word ‘approaches’ – it’s never 0%. If we have business analysts/testers who can focus solely on parts of this task, great – they will extract things we would miss.
Take the opportunity to document the solution as we go, if it hasn’t already been done.
Also take the opportunity to do some cleanup, if scope allows. Unused databases, phantom logins, etc. The less we need to migrate, the better.
Decide ahead of time which new features to enable, if any, and why. The same goes for fixing any outdated settings, like bumping CTFP up from 5. You may want/need to just leave everything as-is initially, but you might then have scope for a ‘phase 2’ where improvements are introduced once stability is established.
Related to the above point, make use of the ability to keep Compatibility Mode at its existing level, if risk tolerance requires it.
Post-migration, be sure to run CHECKDB (additionally using the DATA_PURITY option if a source database(s) was created prior to 2005) and update stats and views.
The Cloud
PaaS (Azure SQL DB, MI) changes things.
We don’t need to worry about upgrading anymore, because there’s one version of the product – constantly tested and updated by Microsoft. That’s great! – but it also means we’re at their mercy and they could potentially apply a patch that breaks something.
This is simply part of the great cloud tradeoff. We hand over responsibility for hardware, OS and software patching but at the same time lose control of it. We can’t have our cake and eat it, too.
But one thing to be said for surrendering this ability is that the more we use Azure – the more data Microsoft has to analyse, the more databases to test on, and the more reliable the whole process should get.
I think it’s a tradeoff worth making for systems suitable for Azure.
Sometimes it’s good to look back and appreciate what we have and how far we’ve come. This applies to many things, but today I’m talking about the humble hard drive.
My first hard drive, as a 7 year old learning the delights of Windows 95, was 1.5GB. I can only guess it was very slow – especially paired with a 133Mhz Pentium 1 – because I recall an inordinate amount of time spent twiddling my thumbs watching the Windows boot logo. Now, my desktop and laptop barely even leave enough time for the (far more drab Windows 10) logo to appear at all, mainly thanks to solid-state drives aka SSDs. They’re everywhere now, but it wasn’t that long ago they were a shiny new thing that had sysadmins and infrastructure engineers acknowledging the speed but wondering about reliability.
While I don’t have any dusty PATA relics available, I thought I’d take a look at a bunch of different drives, throw a couple of SQL workloads at them and have them fight it out. From oldest to newest, the contenders entering the ring are…
Western Digital Blue HDD (4TB) – a ‘spinning rust’ HDD, released 2016 Samsung 860 EVO SSD (256GB) – A SATA3 consumer SSD, released 2018 Samsung 870 EVO SSD (1TB) – A SATA3 consumer SSD, released 2021 Corsair Force MP510 (256GB) – A PCI-E 3.0 NVME SSD, released 2018
Unfortunately I can’t install SQL Server on my PS5, else I’d be able to end this retrospective with its monster PCI-E 4.0 5.5GBps SSD instead. Ah well. Trust me, it’s incredibly fast. Anyway…
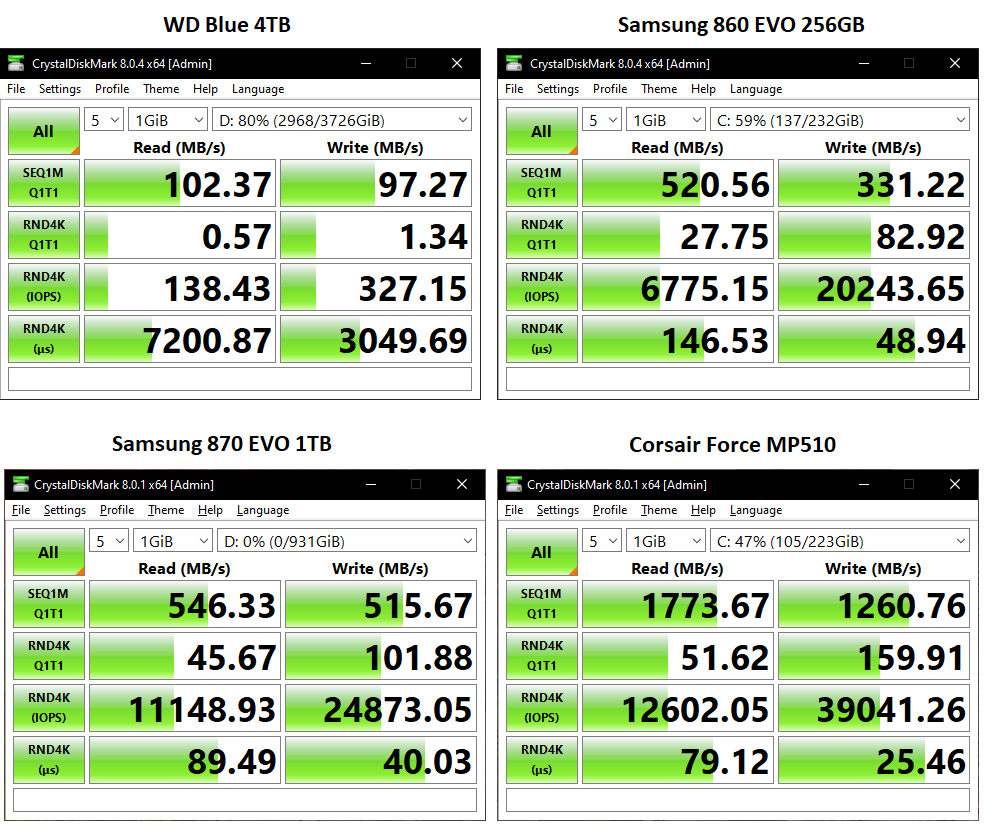
Let’s look at some raw benchmarks first, using CrystalDiskMark set to the ‘Real World Performance’ setting ensuring we aren’t using unrealistic caching or access patterns;
Our MP510 drank his milk and ate his spinach
From HDD, to 256GB SATA SSD, to newer 1TB SATA SSD, to 256GB PCI-E NVME SSD we have;
Sustained read/writes going from 100MB/s to 500MB/s to 1.7GB/s
Random reads going from sub-1MB/s to 30 to 50MB/s
Random writes going from barely 1MB/s to 80, to 100, to 160MB/s
IOPS going from a few hundred to over 9000 to over 100,000
Latency going from milliseconds to hundreds of microseconds to sub-100μs
Big gains all round. In particular, that enormous improvement in random performance and latency is why SSDs make computers feel so snappy. The difference between the two SATA SSDs isn’t much because they’re limited by the interface and most of the gain from the 860 to 870 will be due to it being 1TB thus having more chips to stripe reads and writes across. Additionally, eagle-eyed hardware nerds may have spotted the HDD is 80% full – which significantly reduces its sustained performance. Fair point, but a) it’s still in a similar ballpark and b) I wasn’t going to delete my MP3s and rare film collection just for this test, heh.
The tests
Now for the SQL tests. These were performed on a new database on each drive with any vendor-specific caching turned off and a 4-core CPU of similar spec – first up, create a table and dump 10GB of data into it;
CREATE TABLE dbo.SpeedTest
(
a INT IDENTITY(1,1),
b CHAR(8000)
)
INSERT INTO dbo.SpeedTest (b)
SELECT TOP 1280000 REPLICATE('b',8000)
FROM sys.all_objects ao1
CROSS JOIN sys.all_objects ao2
First test – a table scan of the whole 10GB, and a clearing of the buffer cache beforehand just in case;
DBCC DROPCLEANBUFFERS
SET STATISTICS TIME ON
SELECT COUNT(*)
FROM dbo.SpeedTest
(As expected, a parallel scan using all 4 cores)
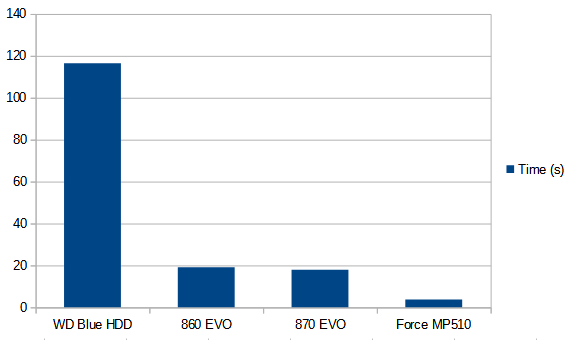
Results;
Who even needs query tuning?
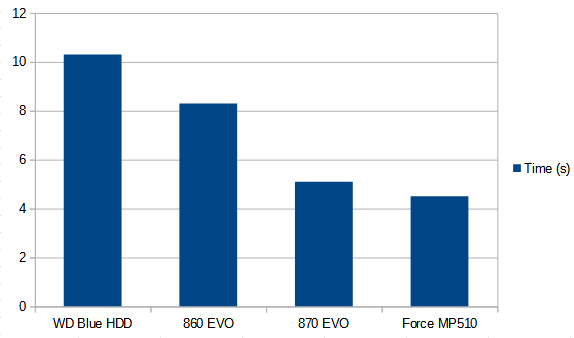
That, folks, is progress. We’ve gone from just under 2 minutes on the HDD, to sub 20 seconds for SATA SSDs, to 3.7 seconds on the PCI-E NVME SSD. Blazin’.
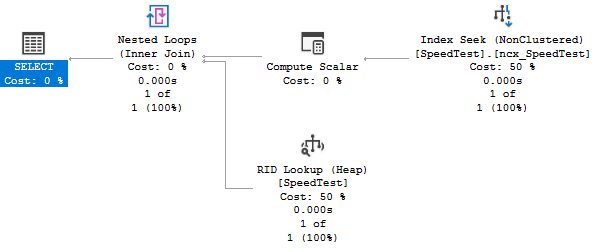
How about seeks? For this I turned to Adam Machanic’s sqlquerystress tool to simulate hammering the database with multiple threads of repeated queries.
First create an index on the identity column to have something to seek;
CREATE NONCLUSTERED INDEX ncx_SpeedTest ON dbo.SpeedTest (a)
And here’s a simple parameterised query, which the tool will substitute values of column a for during successive iterations;
SELECT *
FROM dbo.SpeedTest
WHERE a = @id
Check we’re getting a seek;
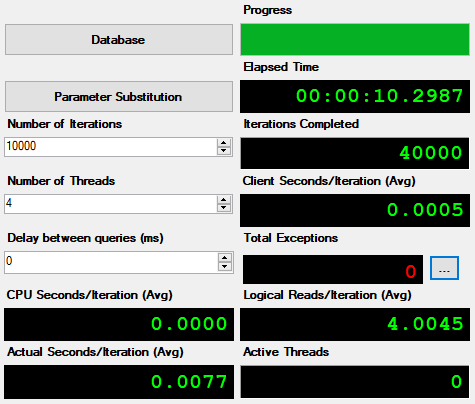
Then set the tool for 10000 iterations on 4 threads, clear buffer cache, and the results look like this for the HDD;
Results for all drives;
The trend continues, albeit without the orders of magnitude gains seen with the scanning test. The NVME SSD is still the winner, but not by much vs the 1TB SATA SSD, which is to be expected since the read IOPS and latency aren’t much better. However – if it was an equally-sized 1TB NVME drive, I’d expect some more gains to be had from the increased IOPs.
Finally let’s look at the unglamourous but crucial task of backing up and restoring. For this test I performed a simple single-file backup and restore to the same drive. This isn’t shouldn’t be a realistic scenario because backups should at the very least be on a different drive if not a dedicated backup server – thus avoiding reading to and writing from the same drive – but I didn’t have an easy way to recreate this and it at least reflects a simultanous read/write workload. Additionally I didn’t see any point splitting the backup into multiple files – which can increase speed – given the r/w contention at play.
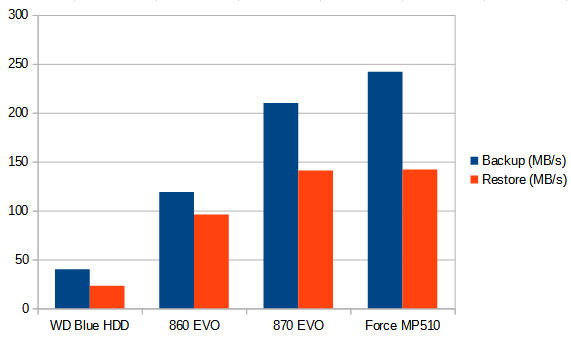
Our poor old HDD doesn’t fare well here – his little heads scrambling back and forth across the platters to try and keep up. And again big gains to SATA SSD and NVME, who’s ~250MB/s backup speed would be far higher if it could write to another NVME SSD.
The verdict
The HDD languishes with poor to relatively awful performance all over. Our SATA SSDs improve in every aspect with enormous gains in sustained performance. Then our PCI-E NVME ushers in a new era of speed, unconstrained by archaic interfaces and, as a bonus, doesn’t even need cables!
That said, from a wider perspective, it’s not all bad news for the humble HDD. They might have poor performance compared to their solid brethren, but remain king for large amounts of storage – they’re made in much bigger sizes (18TB at the moment, with more to come in future), cost less per GB at high sizes and don’t have the same wear problems as SSDs which are only guaranteed for a certain number of ‘drive writes per day’ meaning some write-intensive applications are out.
These days your SQL Servers are probably VMs hooked up to a flash-based SAN, so there’s nothing to learn here on that front. But if you’re somehow still running a desktop or laptop on HDD, I highly recommend switching to at least a SATA SSD, preferably an NVME drive if possible. I added the MP510 tested here to my laptop last year and the speed of the thing is incredible. Additionally – the bigger the better – bigger size equals more chips and channels which equals more speed.
I recently encountered a requirement to estimate the size of (a lot of) nonclustered indexes on some very large tables due to not having a test box to create them on or the time to build one. I couldn’t find a script to do this, and as any programmer knows, laziness is the real mother of invention, so I wrote one. This post summarises how we can calculate this and provides a Powershell function to do so.
I used Microsoft’s documentation as a basis on how to do it, but as it’s a wall of text that’s a little tricky to follow, I’ll go over the basics here. I’m only covering the leaf levels and non-MAX columns that would create LOB pages – I’ll explain why later.
Fundamentally we need to figure out the size of an index record, work out how many fit cleanly on a page, then calculate the total size.
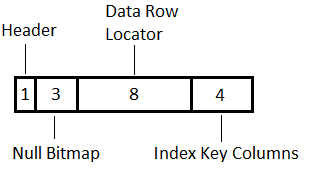
So what’s in an index record?
This, as of SQL 2012, is the most basic record possible. It has;
A header – 1 byte
Null bitmap – minimum 3 bytes, an extra byte for every 8 total columns in the index (so 4 bytes for 9 columns, 5 bytes for 17, etc)
Data row locator – this is either an 8-byte RID if the table is a heap, or the clustered index keys if not.
The index columns themselves – however many columns (key or included) are in the index, aside from clustering keys which are in the DRL.
If there are any variable-length columns present in the index (key, row locator or included), there’s an extra section;
The ‘variable tracker’ is 2 bytes plus 2 bytes for every variable length column (including the uniquifier on a primary key, if it exists).
On top of this, each record takes an extra 2 bytes of a page’s slot array so it can be located – this isn’t on the diagrams as it isn’t part of the record itself.
So the script needs to do the following;
Get the rowcount of the table
Check if the table is a heap or has a clustered index
If the table has a clustered index, is it unique? (does it have a uniquifier)
Count the total number of columns (for the null bitmap)
Count the number of variable-length columns
Calculate the total size of a record, plus the 2 byte slot array entry
Divide that size into 8096 bytes – the usable space on a page – rounding down as only entire rows are stored
Divide that number into the rowcount of the table, and then we have the pages (and thus size) required.
As well as those, I added a few bits of functionality;
Take a rowcount as a parameter, if we don’t want to hit a production table with COUNT_BIG()
Take fillfactor as a parameter in case we’re not using 100 for some reason
Keep track of null columns, as for versions prior to 2012, null bitmaps only exist on leaf pages if at least one column is null.
Script for the function Get-IndexSizeEstimate is at the bottom of the post and on github. It takes an instance name, database, schema, string array of columns for the nonclustered index (including included columns) and optionally the rowcount and fill factor. The SQL and calculation blocks are documented so should be fairly self-explanatory combined with the above information – so onto some demos.
First, using a simple table I used for testing various cases, left as a heap, with 100k rows inserted to generate a few hundred pages;
CREATE TABLE dbo.IndexTesting
(
CustID INT NULL,
OrderID INT NOT NULL,
IndexCol1 INT NOT NULL,
IndexCol2 INT NULL,
VarIndexCol1 VARCHAR(4) NOT NULL,
VarIndexCol2 VARCHAR(10) NOT NULL
)
GO
INSERT INTO dbo.IndexTesting (CustID, OrderID, IndexCol1, IndexCol2, VarIndexCol1, VarIndexCol2)
VALUES (1,2,3,4,'test','test')
GO 100000
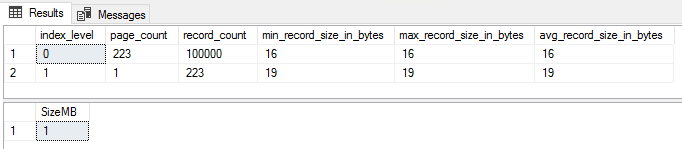
If we want to create a single column index on IndexCol1 (4 bytes), the record should look like this;
for a total of 16 bytes.
Run the script for a single column index on IndexCol1;
We can see the use of the 8-byte RID as row locator, the minimum null bitmap and no variable-width bytes as expected. Create the index and see if we’re close;
SELECT index_level, page_count, record_count, min_record_size_in_bytes, max_record_size_in_bytes, avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.IndexTesting'),2,NULL,'DETAILED')
SELECT SUM(used_page_count) * 8 / 1024 AS 'SizeMB'
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats p
ON p.[object_id] = i.[object_id]
AND i.index_id = p.index_id
WHERE i.[name] = 'ncx_test'
Bang on, 223 pages and 1MB.
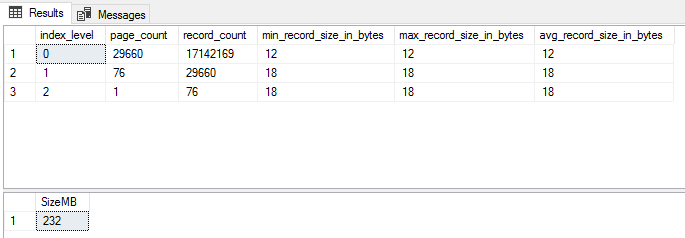
Now for some more real-world examples. A simple test case on a big table – using dbo.Posts from the StackOverflow2013 database, and choosing an index on OwnerUserId.
29658 pages and 232MB is the estimate – and note the row locator is now just 4 bytes, as it’s using the clustered index key instead of the RID in previous example.
Create the index and see how it stacks up (no pun intended);
CREATE NONCLUSTERED INDEX ncx_Posts_OwnerUserId
ON dbo.Posts (OwnerUserId)
SELECT index_level, page_count, record_count, min_record_size_in_bytes, max_record_size_in_bytes, avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Posts'),2,NULL,'DETAILED')
SELECT SUM(used_page_count) * 8 / 1024 AS 'SizeMB'
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats p
ON p.[object_id] = i.[object_id]
AND i.index_id = p.index_id
WHERE i.[name] = 'ncx_Posts_OwnerUserId'
Not bad – just 2 pages out, and the same size after rounding to MB.
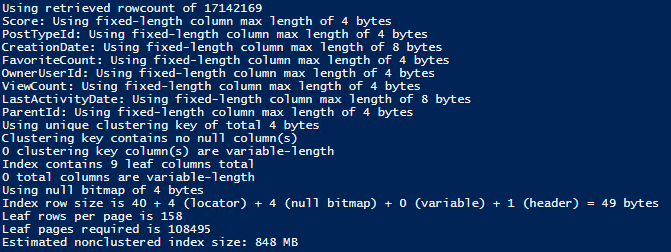
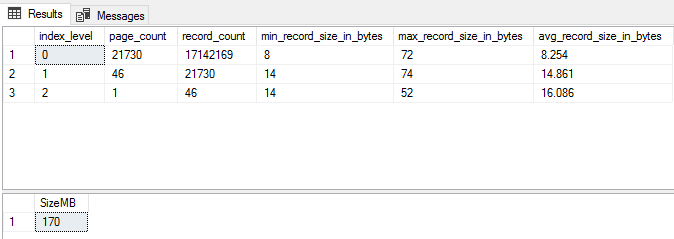
108495 pages and 848MB. Note how since we have 9 total columns in the index when including the primary key, the null bitmap has spilled into 4 bytes.
Build the index and take a look;
CREATE NONCLUSTERED INDEX ncx_Posts_WideIndex
ON dbo.Posts (Score,PostTypeId,CreationDate,FavoriteCount,OwnerUserId,ViewCount,LastActivityDate,ParentId)
SELECT index_level, page_count, record_count, min_record_size_in_bytes, max_record_size_in_bytes, avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Posts'),4,NULL,'DETAILED')
SELECT SUM(used_page_count) * 8 / 1024 AS 'SizeMB'
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats p
ON p.[object_id] = i.[object_id]
AND i.index_id = p.index_id
WHERE i.[name] = 'ncx_Posts_WideIndex'
One page out and a 5MB undershoot – again, not bad! This is also an example of how, even with a wide (in column number terms) index, the contribution of the non-leaf levels is minor. They explain the 5MB discrepancy – and that’s just ~0.5% of the total size. This is the first reason I didn’t include calculations for the non-leaf levels of the index.
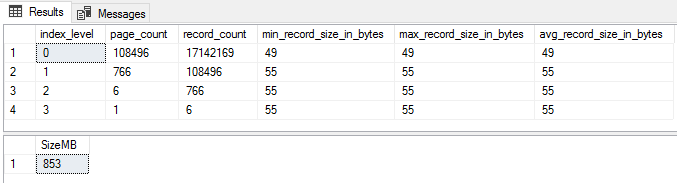
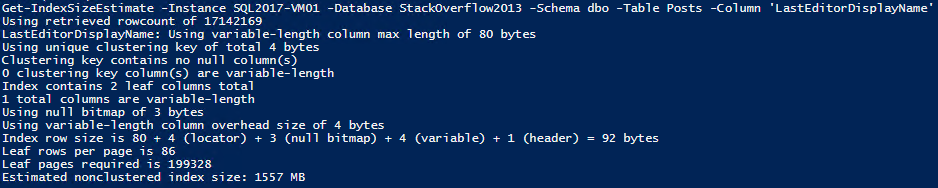
Now for an example of where the estimate can be way off. Using dbo.Posts again, but this time estimating for an index on LastEditorDisplayName, which is a nullable NVARCHAR(40) column.
That’s ~200k pages and 1.5GB. Create the index and take a look;
CREATE NONCLUSTERED INDEX ncx_Posts_DisplayName
ON dbo.Posts (LastEditorDisplayName)
SELECT index_level, page_count, record_count, min_record_size_in_bytes, max_record_size_in_bytes, avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Posts'),3,NULL,'DETAILED')
SELECT SUM(used_page_count) * 8 / 1024 AS 'SizeMB'
FROM sys.indexes i
INNER JOIN sys.dm_db_partition_stats p
ON p.[object_id] = i.[object_id]
AND i.index_id = p.index_id
WHERE i.[name] = 'ncx_Posts_DisplayName'
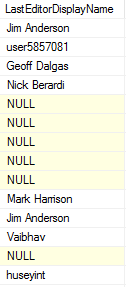
Ouch. That’s an order-of-magnitude overestimate. Why? Take a look at the record size figures. Min 8, max 72, and an average barely over the minimum. Taking a glance at the table shows it appears to be sparsely populated, and with names that are much less than 40 characters to boot;
Well, there’s the rub. When variable length or null columns are included, the estimate can be nigh-on useless, depending on the distribution of data. Yep, there are things that could be done to get a better estimate – like taking a string array of parameters for ‘estimated null percent’ or ‘estimated varchar usage percent’, or going beyond guesses by calculating those figures from sampling/scanning the table…but at this point, a) the code starts getting increasingly complicated, b) we’re potentially needing to hit the database with some hefty queries and c) …it’s still not going to be completely accurate, so if it needs to be, we best get that test box set up. This is why I didn’t attempt to take non-leaf levels, LOB pages or variable-length column usage (script assumes maximum length) into account – it is an estimate, after all.
That said, I hope it proves useful to someone for the scenario it works well for – fixed-length column indexes. Code is below.
function Get-IndexSizeEstimate
{
<#
.SYNOPSIS
Returns estimated index size for a given column in a table
.DESCRIPTION
Calculates leaf-level index size for a given column in a table and returns the calculation and value in MB
.PARAMETER Instance
Specifies the SQL instance name
.PARAMETER Database
Specifies the database name
.PARAMETER Schema
Specifies the schema name
.PARAMETER Table
Specifies the table name
.PARAMETER Column
Specifies the column name(s)
.PARAMETER Rows
Specifies the number of rows to calculate for instead of querying the table for COUNT()
.PARAMETER Fillfactor
Specifies the fillfactor (1-100) to use (default 100)
.OUTPUTS
Index leaf-level estimated size
.EXAMPLE
PS> Get-IndexSizeEstimate -Instance SQL2017-VM01 -Database TestDB -Schema dbo -Table IndexTesting -Column IndexCol1,VarIndexCol2
Using retrieved rowcount of 100000
Using variable-length column max length of 4 bytes
Using unique clustering key of total 4 bytes
Clustering key contains no null column(s)
0 clustering key column(s) are variable-length
Index contains 2 leaf columns total
1 total columns are variable-length
Using null bitmap of 3 bytes
Using variable-length column overhead size of 4 bytes
Index row size is 4 + 4 + 3 (null bitmap) + 4 (variable) + 1 (header) = 16 bytes
Leaf rows per page is 449
Leaf pages required is 223
Estimated nonclustered index size: 2 MB
#>
param
(
[Parameter(position=0, mandatory=$true)][string]$Instance,
[Parameter(position=1, mandatory=$true)][string]$Database,
[Parameter(position=2, mandatory=$true)][string]$Schema,
[Parameter(position=3, mandatory=$true)][string]$Table,
[Parameter(position=4, mandatory=$true)][string[]]$Column,
[Parameter(position=5, mandatory=$false)][long]$Rows,
[Parameter(position=6, mandatory=$false)][int]$Fillfactor
)
Import-Module SqlServer
###### Pre-checks ######
# Parameter checks
if($Rows -and $Rows -lt 1)
{
Write-Output "Rows parameter must be at least 1"
return
}
if($Fillfactor -and ($Fillfactor -le 0 -or $Fillfactor -gt 100))
{
Write-Output "Fillfactor must be an integer between 1 and 100"
return;
}
# Check database exists and is online
$query = "SELECT 1
FROM sys.databases
WHERE [name] = '$($Database)'
AND state_desc = 'ONLINE'"
try
{
$check = Invoke-Sqlcmd -ServerInstance $Instance -Database master -Query $query -ConnectionTimeout 3 -QueryTimeout 3 -ErrorAction Stop
if(!$check)
{
Write-Output "Error - database does not exist or is offline."
return
}
}
catch
{
Write-Output "Error - can't connect to instance."
Write-Output $error[0]
return
}
# Check schema/table/column(s) exists
foreach($col in $Column)
{
$query = "SELECT 1
FROM sys.tables t
INNER JOIN sys.schemas s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.columns c
ON t.[object_id] = c.[object_id]
INNER JOIN sys.types ty
ON c.user_type_id = ty.user_type_id
WHERE s.[name] = '$($Schema)'
AND t.[name] = '$($Table)'
AND c.[name] = '$($col)'"
try
{
$check = Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 10 -QueryTimeout 300 -ErrorAction Stop
if(!$check)
{
Write-Output "Error - schema/table/column doesn't exist for $($col)"
return;
}
}
catch
{
Write-Output "Error connecting to instance."
Write-Output $error[0]
return
}
}
# Get SQL version
$query = "SELECT SUBSTRING(CONVERT(VARCHAR(128), SERVERPROPERTY('productversion')), 1, CHARINDEX('.', CONVERT(VARCHAR(128), SERVERPROPERTY('productversion')), 1) - 1) AS 'Version'"
try
{
[int]$sqlversion = (Invoke-Sqlcmd -ServerInstance $Instance -Database master -Query $query -ConnectionTimeout 5 -QueryTimeout 5 -ErrorAction Stop).Version
}
catch
{
Write-Output "Error retrieving SQL version"
Write-Output $error[0]
return
}
###### Code body ######
# Variable decarations
$leafcolumns = 0
$keylength = 0
$nullcolumns = $false
$nullbitmap = 0
$variablecolumns = 0
$variableoverheadsize = 0
$variablecolumnlist = 'text', 'ntext', 'image', 'varbinary', 'varchar', 'nvarchar'
# Get rowcount of table if not passed as parameter
if($Rows)
{
$rowcount = $Rows
Write-Output "Using passed rowcount of $($rowcount)"
}
else
{
$query = "SELECT COUNT_BIG(*) AS 'Rowcount'
FROM $($Schema).$($Table)"
try
{
$rowcount = (Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 10 -QueryTimeout 300 -ErrorAction Stop).Rowcount
if($rowcount -eq 0)
{
Write-Output "Table is empty. Aborting function"
return
}
Write-Output "Using retrieved rowcount of $($rowcount)"
}
catch
{
Write-Output "Error retrieving rowcount."
Write-Output $error[0]
return
}
}
# Get key column(s) length/nullability and increment leaf and variable key counters
foreach($col in $Column)
{
$query = "SELECT c.is_nullable, c.max_length AS 'MaxLength', ty2.[Name]
FROM sys.tables t
INNER JOIN sys.schemas s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.columns c
ON t.[object_id] = c.[object_id]
INNER JOIN sys.types ty
ON c.user_type_id = ty.user_type_id
INNER JOIN sys.types ty2
ON ty.system_type_id = ty2.user_type_id
WHERE s.[name] = '$($Schema)'
AND t.[name] = '$($Table)'
AND c.[name] = '$($col)'"
try
{
$result = Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 5 -QueryTimeout 5 -ErrorAction Stop
$keylength += $result.MaxLength
$leafcolumns++
# Set null columns flag true if index column is nullable (used for SQL < 2012)
if($result.is_nullable)
{
$nullcolumns = $true
}
if($variablecolumnlist -contains $result.Name)
{
$variablecolumns++
Write-Output "$($col): Using variable-length column max length of $($result.MaxLength) bytes"
}
else
{
Write-Output "$($col): Using fixed-length column max length of $($result.MaxLength) bytes"
}
}
catch
{
Write-Output "Error retrieving column max length"
Write-Output $error[0]
return
}
}
# Get clustered index size, nullability, column count and uniqueness (if exists)
$query = "SELECT i.is_unique, MAX(CAST(is_nullable AS TINYINT)) AS 'NullColumns', COUNT(*) AS 'NumKeyCols', SUM(c.max_length) AS 'SummedMaxLength'
FROM sys.tables t
INNER JOIN sys.schemas s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.indexes i
ON t.[object_id] = i.[object_id]
INNER JOIN sys.index_columns ic
ON i.[object_id] = ic.[object_id]
AND i.index_id = ic.index_id
INNER JOIN sys.columns c
ON ic.[object_id] = c.[object_id]
AND ic.column_id = c.column_id
WHERE s.[name] = '$($Schema)'
AND t.[name] = '$($Table)'
AND i.[type] = 1
GROUP BY i.is_unique"
try
{
$clusteringkey = Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 5 -QueryTimeout 5 -ErrorAction Stop
# If there's no clustering key
if(!$clusteringkey)
{
# Use value for heap RID (8 bytes)
$rowlocatorlength = 8
Write-Output "Table is a heap, using RID of 8 bytes"
}
else
{
# Increment leaf column count by clustering key count
$leafcolumns += $clusteringkey.NumKeyCols
if($clusteringkey.is_unique -eq 1)
{
$rowlocatorlength = $clusteringkey.SummedMaxLength
Write-Output "Using unique clustering key of total $($rowlocatorlength) bytes"
}
else
{
# Need to add 4 bytes for uniquifier, and also increment $variablecolumns
$rowlocatorlength = $clusteringkey.SummedMaxLength + 4
$variablecolumns++
Write-Output "Using nonunique clustering key of total $($rowlocatorlength) bytes with uniquifier"
}
# Check if any null columns exist in clustering key and set flag if so
if($clusteringkey.NullColumns -eq 1)
{
$nullcolumns = $true
Write-Output "Clustering key contains null column(s)"
}
else
{
Write-Output "Clustering key contains no null column(s)"
}
# Get count of clustering key variable colunns
$query = "SELECT COUNT(*) AS 'Count'
FROM sys.tables t
INNER JOIN sys.schemas s
ON t.[schema_id] = s.[schema_id]
INNER JOIN sys.indexes i
ON t.[object_id] = i.[object_id]
INNER JOIN sys.index_columns ic
ON i.[object_id] = ic.[object_id]
AND i.index_id = ic.index_id
INNER JOIN sys.columns c
ON ic.[object_id] = c.[object_id]
AND ic.column_id = c.column_id
INNER JOIN sys.types ty
ON c.user_type_id = ty.user_type_id
INNER JOIN sys.types ty2
ON ty.system_type_id = ty2.user_type_id
WHERE s.[name] = '$($schema)'
AND t.[name] = '$($Table)'
AND i.[type] = 1
AND ty2.[name] IN ('text', 'ntext', 'image', 'varbinary', 'varchar', 'nvarchar')"
$variableclusteringcolumns = (Invoke-Sqlcmd -ServerInstance $Instance -Database $Database -Query $query -ConnectionTimeout 5 -QueryTimeout 5 -ErrorAction Stop).Count
Write-Output "$($variableclusteringcolumns) clustering key column(s) are variable-length"
$variablecolumns += $variableclusteringcolumns
}
}
catch
{
Write-Output "Error retrieving clustering key info"
Write-Output $error[0]
return
}
Write-Output "Index contains $($leafcolumns) leaf columns total"
if(($nullcolumns) -and ($sqlversion -lt 11))
{
Write-Output "Leaf record contains null columns"
}
Write-Output "$($variablecolumns) total columns are variable-length"
# Calculate null bitmap size
# If version is >= 2012 or null columns exist, add null bitmap - else don't add
if(($sqlversion -ge 11) -or ($nullcolumns -eq $true))
{
$nullbitmap = [Math]::Floor(2 + (($leafcolumns + 7) / 8))
Write-Output "Using null bitmap of $($nullbitmap) bytes"
}
# Calculate variable-length overhead size
if($variablecolumns -gt 0)
{
$variableoverheadsize = 2 + ($variablecolumns * 2)
Write-Output "Using variable-length column overhead size of $($variableoverheadsize) bytes"
}
# Calculate total index size
$indexsize = $keylength + $rowlocatorlength + $nullbitmap + $variableoverheadsize + 1
Write-Output "Index row size is $($keylength) + $($rowlocatorlength) (locator) + $($nullbitmap) (null bitmap) + $($variableoverheadsize) (variable) + 1 (header) = $($indexsize) bytes"
# Calculate leaf rows per page - adding 2 bytes to indexsize for slot array entry
$leafrowsperpage = [Math]::Floor(8096 / ($indexsize + 2))
Write-Output "Leaf rows per page is $leafrowsperpage"
# Use full pages if not specifying fillfactor
if(!$Fillfactor)
{
$leafpages = [Math]::Ceiling($rowcount / $leafrowsperpage)
Write-Output "Leaf pages required is $($leafpages)"
}
else
{
Write-Output "Using fillfactor of $($Fillfactor)"
$freerowsperpage = [Math]::Floor(8096 * ((100 - $Fillfactor) / 100) / ($indexsize + 2))
$leafpages = [Math]::Ceiling($rowcount / ($leafrowsperpage - $freerowsperpage))
Write-Output "Leaf pages required is $($leafpages)"
}
###### Final result ######
$estimate = $leafpages * 8192
$estimateMB = [Math]::Round($estimate / 1024 / 1024)
Write-Output "Estimated nonclustered index size: $($estimateMB) MB"
}
While testing a script that involved calculating index record size recently I was getting some confusing results depending on server version, and after some digging it appears there was a somewhat undocumented change to nonclustered index leaf page structure in SQL Server 2012.
Prior to 2012, as dicussed by Paul Randal in this 2010 blog post (which is still the top result for searching for ‘nonclustered index null bitmap’, hence this post) the null bitmap – that is, a >= 3 byte structure representing null fields in a record – was essentially present in all data pages but not the leaf pages of a nonclustered index that had no nulls in either the index key or any clustering key columns.
This is easy to re-demonstrate with the same simple example table from that post. Using SQL 2008R2, create the table, then pull the pages of the heap with DBCC IND;
CREATE TABLE dbo.NullTest (c1 INT NOT NULL)
CREATE NONCLUSTERED INDEX ncx_test
ON dbo.NullTest (c1)
INSERT INTO dbo.NullTest (c1)
VALUES (1)
DBCC IND ('TestDB', 'NullTest', 0)
PagePID 153 – the page at IndexLevel 0 – is the data page containing the record, so let’s look at that with DBCC PAGE – specifically, the DATA records;
DBCC PAGE ('TestDB',1,153,1) WITH TABLERESULTS
So we have a NULL_BITMAP attribute, and a record size of 11 bytes. That’s 4 bytes of header, 4 bytes for the INT, 3 bytes for the null bitmap = 11 bytes.
Now pull the pages of the nonclustered index;
DBCC IND ('TestDB', 'NullTest', 2)
This time we want to run DBCC PAGE on PagePID 155, again at IndexLevel = 0;
DBCC PAGE ('TestDB',1,155,1) WITH TABLERESULTS
Now we get an empty ‘Record Attributes’ field, and a size of 13 bytes. This makes sense – the index key itself is 4 bytes, there are 8 bytes for the data row locator (RID), 1 byte for the row header, and we don’t have those 3 bytes of null bitmap anymore.
Now let’s try the same on SQL 2012. Create the same table and index, and pull the data page;
CREATE TABLE dbo.NullTest (c1 INT NOT NULL)
CREATE NONCLUSTERED INDEX ncx_test
ON dbo.NullTest (c1)
INSERT INTO dbo.NullTest (c1)
VALUES (1)
DBCC IND ('TestDB', 'NullTest', 0)
DBCC PAGE ('TestDB',1,296,1) WITH TABLERESULTS
So far, the same.
Now for the index record;
DBCC IND ('TestDB', 'NullTest', 2)
DBCC PAGE ('TestDB',1,304,1) WITH TABLERESULTS
This time, we have a NULL_BITMAP attribute and a record size of 16. That’s 4 bytes of index key, 8 bytes of RID, 3 bytes of null bitmap and 1 byte of header.
(This is unrelated to compatibility level – running this test on a level 100 database on SQL 2012 returns the same results.)
I can’t find a link to any kind of change documentation for this, but it is subtly informed by the Microsoft documentation for estimating the size of a nonclustered index. In that document, while non-leaf records have a ‘if there are any nullable columns …‘ caveat, the formula given for leaf records is simply Leaf_Null_Bitmap = 2 + ((Num_Leaf_Cols + 7) / 8), implying it’s always there.